
What is Index Scans/Table Scans and What is Bookmark/Key/RID lookup and How is Discovering Unused Indexes?
An index scan or table scan is when SQL Server has to scan the data or index pages to find the appropriate records. A scan is the opposite of a seek, where a seek uses the index to pinpoint the records that are needed to satisfy the query. The reason you would want to find and fix your scans is because they generally require more I/O and also take longer to process. This is something you will notice with an application that grows over time. When it is first released performance is great, but over time as more data is added the index scans take longer and longer to complete.
To find these issues you can start by running Profiler or setting up a server side trace and look for statements that have high read values. Once you have identified the statements then you can look at the query plan to see if there are scans occurring.
Here is a simple query that we can run. First use Ctrl+M to turn on the actual execution plan and then execute the query.
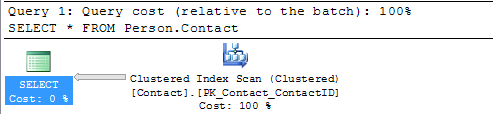
SELECT * FROM Person.Contact
Here we can see that this query is doing a Clustered Index Scan. Since this table has a clustered index and there is not a WHERE clause SQL Server scans the entire clustered index to return all rows. So in this example there is nothing that can be done to improve this query.
 In this next example I created a new copy of the Person.Contact table without a clustered index and then ran the query.
SELECT * FROM Person.Contact2
Here we can see that this query is doing a Table Scan, so when a table has a Clustered Index it will do a Clustered Index Scan and when the table does not have a clustered index it will do a Table Scan. Since this table does not have a clustered index and there is not a WHERE clause SQL Server scans the entire table to return all rows. So again in this example there is nothing that can be done to improve this query.
In this next example I created a new copy of the Person.Contact table without a clustered index and then ran the query.
SELECT * FROM Person.Contact2
Here we can see that this query is doing a Table Scan, so when a table has a Clustered Index it will do a Clustered Index Scan and when the table does not have a clustered index it will do a Table Scan. Since this table does not have a clustered index and there is not a WHERE clause SQL Server scans the entire table to return all rows. So again in this example there is nothing that can be done to improve this query.
 In this next example we include a WHERE clause for the query.
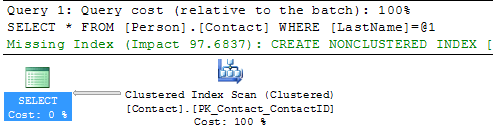
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
Here we can see that we still get the Clustered Index Scan, but this time SQL Server is letting us know there is a missing index. If you right click on the query plan and select Missing Index Details you will get a new window with a script to create the missing index.
In this next example we include a WHERE clause for the query.
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
Here we can see that we still get the Clustered Index Scan, but this time SQL Server is letting us know there is a missing index. If you right click on the query plan and select Missing Index Details you will get a new window with a script to create the missing index.
 Let's do the same thing for our Person.Contact2 table.
SELECT * FROM Person.Contact2 WHERE LastName = 'Russell'
We can see that we still have the Table Scan, but SQL Server doesn't offer any suggestions on how to fix this.
Let's do the same thing for our Person.Contact2 table.
SELECT * FROM Person.Contact2 WHERE LastName = 'Russell'
We can see that we still have the Table Scan, but SQL Server doesn't offer any suggestions on how to fix this.
 Another thing you could do is use the Database Engine Tuning Advisor to see if it gives you any suggestions. If I select the query in SSMS, right click and select Analyze Query in Database Engine Tuning Advisor the tools starts up and I can select the options and start the analysis.
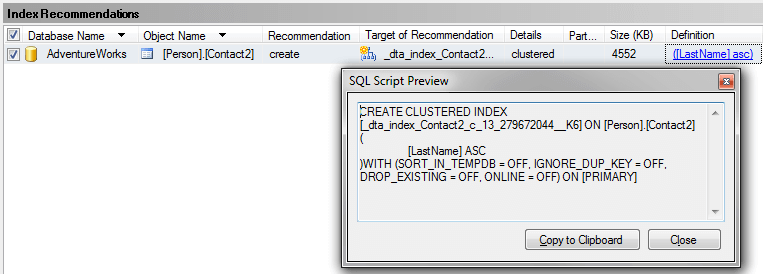
Below is the suggestion this tool provides and we can see that recommends creating a new index, so you can see that using both tools can be beneficial.
Another thing you could do is use the Database Engine Tuning Advisor to see if it gives you any suggestions. If I select the query in SSMS, right click and select Analyze Query in Database Engine Tuning Advisor the tools starts up and I can select the options and start the analysis.
Below is the suggestion this tool provides and we can see that recommends creating a new index, so you can see that using both tools can be beneficial.
Create New Index
So let's create the recommended index on Person.Contact and run the query again.
USE [AdventureWorks]
GO
CREATE NONCLUSTERED INDEX [IX_LastName]
ON [Person].[Contact] ([LastName])
GO
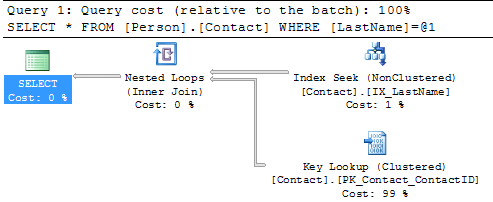
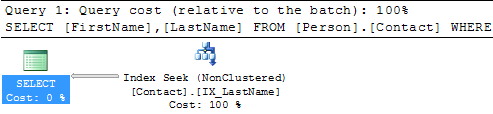
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
Here we can see the query plan has changed and instead of a Clustered Index Scan we now have an Index Seek which is much better. We can also see that there is now a Key Lookup operation which we will talk about in the next section.
USE [AdventureWorks] GO CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].[Contact] ([LastName]) GO SELECT * FROM Person.Contact WHERE LastName = 'Russell'
Summary
By finding and fixing your Index Scans and Table Scans you can drastically improve performance especially for larger tables. So take the time to identify where your scans may be occurring and create the necessary indexes to solve the problem. One thing that you should be aware of is thattoo many indexes also causes issues, so make sure you keep a balance on how many indexes you create for a particular table.
Eliminating bookmark /Key & Rid lookups
In the above scenario, if table has clustered index, it is called bookmark lookup (or key lookup); if the table does not have clustered index, but a non-clustered index, it is called RID lookup. This operation is very expensive. To optimize any query containing bookmark lookup or RID lookup, it should be removed from the execution plan to improve performance. There are two different ways to remove bookmark/RID lookup.
The reason you would want to eliminate Key/RID Lookups is because they require an additional operation to find the data and may also require additional I/O. I/O is one of the biggest performance hits on a server and any way you can eliminate or reduce I/O is a performance gain.
So let's take a look at an example query and the query plan. Before we do this we want to first add the nonclustered index on LastName.
USE [AdventureWorks]
GO
CREATE NONCLUSTERED INDEX [IX_LastName]
ON [Person].[Contact] ([LastName])
GO
Now we can use Ctrl+M to turn on the actual execution plan and run the select.
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
If we look at the execution plan we can see that we have an Index Seek using the new index, but we also have a Key Lookup on the clustered index. The reason for this is that the nonclustered index only contains the LastName column, but since we are doing a SELECT * the query has to get the other columns from the clustered index and therefore we have a Key Lookup. The other operator we have is the Nested Loops this joins the results from the Index Seek and the Key Lookup.
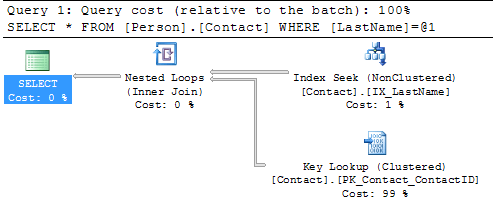 So if we change the query as follows and run this again you can see that the Key Lookup disappears, because the index includes all of the columns.
So if we change the query as follows and run this again you can see that the Key Lookup disappears, because the index includes all of the columns.
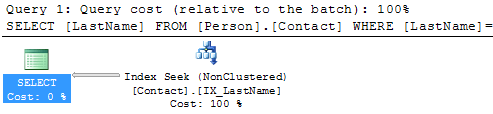
SELECT LastName FROM Person.Contact WHERE LastName = 'Russell'
Here we can see that we no longer have a Key Lookup and we also no longer have the Nested Loops operator.
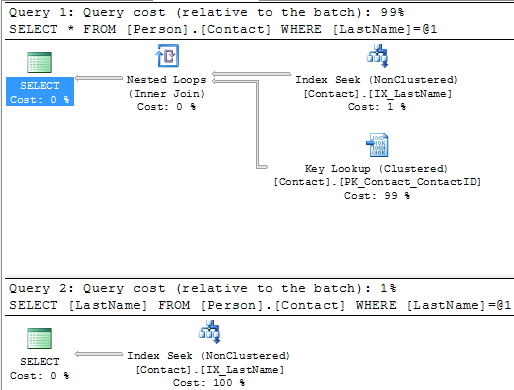
 If we run both of these queries at the same time in one batch we can see the improvement by removing these two operators.
If we run both of these queries at the same time in one batch we can see the improvement by removing these two operators.
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
SELECT LastName FROM Person.Contact WHERE LastName = 'Russell'
Below we can see that the first statement takes 99% of the batch and the second statement takes 1%, so this is a big improvement.
 This should make sense that since the index includes LastName and that is the only column that is being used for both the SELECTed columns and the WHERE clause the index can handle the entire query. Another thing to be aware of is that if the table has a clustered index we can include the clustered index column or columns as well without doing a Key Lookup.
The Person.Contact table has a clustered index on ContactID, so if we include this column in the query we can still do just an Index Seek.
This should make sense that since the index includes LastName and that is the only column that is being used for both the SELECTed columns and the WHERE clause the index can handle the entire query. Another thing to be aware of is that if the table has a clustered index we can include the clustered index column or columns as well without doing a Key Lookup.
The Person.Contact table has a clustered index on ContactID, so if we include this column in the query we can still do just an Index Seek.
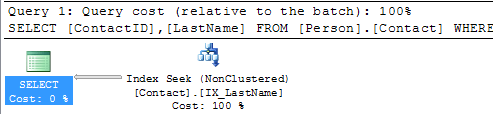
SELECT ContactID, LastName FROM Person.Contact WHERE LastName = 'Russell'
Here we can see that we only need to do an Index Seek to include both of these columns.
 So that's great if that is all you need, but what if you need to include other columns such as FirstName. If we change the query as follows then the Key Lookup comes back again.
So that's great if that is all you need, but what if you need to include other columns such as FirstName. If we change the query as follows then the Key Lookup comes back again.
SELECT FirstName, LastName FROM Person.Contact WHERE LastName = 'Russell'
Luckily there are a few options to handle this.
USE [AdventureWorks] GO CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].[Contact] ([LastName]) GO
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
SELECT LastName FROM Person.Contact WHERE LastName = 'Russell'
SELECT * FROM Person.Contact WHERE LastName = 'Russell' SELECT LastName FROM Person.Contact WHERE LastName = 'Russell'
SELECT ContactID, LastName FROM Person.Contact WHERE LastName = 'Russell'
SELECT FirstName, LastName FROM Person.Contact WHERE LastName = 'Russell'
Creating a Covering Index
A covering index basically does what it implies, it covers the query by including all of the columns that are needed. So if our need is to always include FirstName and LastName we can modify our index as follows to include both LastName and FirstName.
DROP INDEX [IX_LastName] ON [Person].[Contact]
GO
CREATE NONCLUSTERED INDEX [IX_LastName]
ON [Person].[Contact] ([LastName], [FirstName])
GO
And if we look at the execution plan we can see that we eliminated the Key Lookup once again.
DROP INDEX [IX_LastName] ON [Person].[Contact] GO CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].[Contact] ([LastName], [FirstName]) GO
Creating an Index with Included Columns
Another option is to use the included columns feature for an index. This allows you to include additional columns so they are stored with the index, but are not part of the index tree. So this allows you to take advantage of the features of a covering index and reduces storage needs within the index tree. Another benefit is that you can include additional data types that can not be part of a covering index.
The syntax for the the index with included columns is as follows:
DROP INDEX [IX_LastName] ON [Person].[Contact]
GO
CREATE NONCLUSTERED INDEX [IX_LastName]
ON [Person].[Contact] ([LastName])
INCLUDE ([FirstName])
GO
Here we can see the exuection plan is the same for both options.
DROP INDEX [IX_LastName] ON [Person].[Contact] GO CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].[Contact] ([LastName]) INCLUDE ([FirstName]) GO
Another Examples to
Remove Bookmark Lookup (or) Key Lookup(Table have Clustered index):
When a small number of rows are requested by a query, the SQL Server optimizer will try to use a non-clustered index on the column or columns contained in the WHERE clause to retrieve the data requested by the query. If the query requests data from columns not present in the non-clustered index, SQL Server must go back to the data pages to get the data in those columns. Even if the table has a clustered index or not, the query will still have to return to the table or clustered index to retrieve the data.
When a small number of rows are requested by a query, the SQL Server optimizer will try to use a non-clustered index on the column or columns contained in the WHERE clause to retrieve the data requested by the query. If the query requests data from columns not present in the non-clustered index, SQL Server must go back to the data pages to get the data in those columns. Even if the table has a clustered index or not, the query will still have to return to the table or clustered index to retrieve the data.
In the above scenario, if table has clustered index, it is called bookmark lookup (or key lookup); if the table does not have clustered index, but a non-clustered index, it is called RID lookup.
This operation is very expensive. To optimize any query containing
bookmark lookup or RID lookup, it should be removed from the execution
plan to improve performance. There are two different ways to remove
bookmark/RID lookup.
let us understand the difference between Seek Predicate and Predicate. Seek Predicate is the operation that describes the b-tree portion of the Seek. Predicate is the operation that describes the additional filter using non-key columns. Based on the description, it is very clear that Seek Predicate is better than Predicate as it searches indexes whereas in Predicate, the search is on non-key columns – which implies that the search is on the data in page files itself.
Let us see an example where we will remove the bookmark lookup first using the covering index. On removing the bookmark lookup, it resulted in Index Scan, which is not good for performance. When Index Scan is converted to Index Seek, it provides a significant improvement in performance.
Run following SELECT, which is based on the database AdventureWorks.
USE AdventureWorks
GO-- CTRL + M Enforces Key Lookup
-- Try 1SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = 14417807
GO
Let us check the execution plan for the same. The execution plan consists of the key lookup because there are columns that we are trying to retrieve in SELECT as well in WHERE clause.

Let us create a covering index on this table HumanResources.Employee.
-- Create Non clustered IndexCREATE NONCLUSTERED INDEX [IX_HumanResources_Employee_Example] ON HumanResources.Employee(NationalIDNumber ASC, HireDate, MaritalStatus) ON [PRIMARY] GO
After creating above index, let us run the same SELECT statement again.
-- CTRL + M Removes Key Lookup, but it still enforces Index Scan
-- Try 2SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = 14417807
GO
Due to non-clustered index, Key Lookup is removed along with Nested Loops but Index Scan still remains, and this is not good for performance.

I tried to remove the scan, but my attempts were unsuccessful. I finally looked at the datatype of the NationalIDNumber. All this time, I was assuming that this datatype is INT, but on a careful check, I found that the datatype of NationalIDNumber is nvarchar(15).

In the SELECT statement, we were comparing the datatype of NVARCHAR to INT, and this was forcing thepredicate operation while executing the query.

As discussed earlier, due to predicate operation, there has to be explicit conversion on the side of NationalIDNumber, which forces the query optimizer to not use the index and instead it has to scan the complete data in table to get the necessary data. This is not the desired solution. Index Scan reduces performance. The reason for this conversion is because I am using INT value in WHERE clause instead of NVARCHAR.
I changed my WHERE clause and passed STRING as the parameter instead of INT.
-- CTRL + M Removes Key Lookup and it enforces Index Seek
-- Try 3SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = '14417807'GO
After running the query with the changed WHERE clause, the Index Scan is now converted into Index Seek.

Index Seek is definitely the most optimal solution in this particular scenario.

When the detail execution plan was checked, I found the following two notable points. First, the predicate is converted to seek predicate, which is the reason for performance improvement, as described earlier. Instead of scanning data in the table, Index Seek is performed. Second, as the datatype of the NationalIDNumber is NVARCHAR and the parameters are passed as VARCHAR, the conversion happens on the parameters instead of NationalIDNumber column, and this forces Index Scan to Index Seek.
If we pass the parameter as NVARCHAR instead of VARCHAR, the execution plan will remain the same, but CONVERT_IMPLICIT will not be required any more. Let us run the following query, which has NVARCHAR as the parameter.
-- CTRL + M Removes Key Lookup and it enforces Index Seek and no CONVERT_IMPLICIT
-- Try 4SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = N'14417807'GO
The execution plan of the above query is very similar to that in which we had passed the parameter as VARCHAR.
Now let us check the execution plan for the same.

In the WHERE condition, the operators we have on both the sides of “=” are of NVARCHAR. NationalIDNumber and parameter passed – both are NVARCHAR, which has removed CONVERT_IMPLICIT. However, there are no changes in the execution plan.
In summary, when Key Lookup is removed and index seek replaces index scan, the performance is tuned up. Let us quickly compare the execution plan of the above four options. I have included the complete code here for easy reference.
USE AdventureWorks
GO-- CTRL + M Enforces Key Lookup
-- Try 1SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = 14417807
GO-- Create Non clustered IndexCREATE NONCLUSTERED INDEX [IX_HumanResources_Employee_Example] ON HumanResources.Employee(NationalIDNumber ASC, HireDate, MaritalStatus) ON [PRIMARY] GO--WAITFOR DELAY '00:00:30'
-- CTRL + M Removes Key Lookup, but it still enforces Index Scan
-- Try 2SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = 14417807
GO-- CTRL + M Removes Key Lookup and it enforces Index Seek
-- Try 3SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = '14417807'GO-- CTRL + M Removes Key Lookup and it enforces Index Seek and no CONVERT_IMPLICIT
-- Try 4SELECT NationalIDNumber, HireDate, MaritalStatusFROM HumanResources.EmployeeWHERE NationalIDNumber = N'14417807'GO/* What is the reason for difference between Try 2 and Try 3?
Check the exeuction plan
*/
-- Drop IndexDROP INDEX [IX_HumanResources_Employee_Example] ON HumanResources.Employee WITH ( ONLINE = OFF )GO
Let us look at the execution plan.

Summary points:
- In general, Index Seek is better than Index Scan (I am not talking about it depends conditions)
- Understand Predicates and Seek Predicates and see if you have only Seek Predicates.
- In case of key lookup or bookmark lookup, see if you can create a covering index or included column index.
- Use the datatype wisely even though there is no change in the resultset.
In the above scenario, if table has clustered index, it is called bookmark lookup (or key lookup); if the table does not have clustered index, but a non-clustered index, it is called RID lookup. This operation is very expensive. To optimize any query containing bookmark lookup or RID lookup, it should be removed from the execution plan to improve performance. There are two different ways to remove bookmark/RID lookup.
Before we understand these two methods, we will create sample table without clustered index and simulate RID lookup. RID Lookup is a bookmark lookup on a heap that uses a supplied row identifier (RID).
USE tempdb
GO-- Create Table OneIndex with few columnsCREATE TABLE OneIndex (ID INT,FirstName VARCHAR(100),LastName VARCHAR(100),City VARCHAR(100))GO-- Insert One Hundred Thousand RecordsINSERT INTO OneIndex (ID,FirstName,LastName,City)SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY a.name) RowID,'Bob',CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)%2 = 1 THEN 'Smith'ELSE 'Brown' END,CASEWHEN ROW_NUMBER() OVER (ORDER BY a.name)%1000 = 1 THEN 'Las Vegas'WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 1 THEN 'New York'WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 5 THEN 'San Marino'WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 3 THEN 'Los Angeles'ELSE 'Houston' END
FROM sys.all_objects aCROSS JOIN sys.all_objects b
GO
Now let us run following select statement and check the execution plan.
SELECT ID, FirstNameFROM OneIndexWHERE City = 'Las Vegas'GO
As there is no index on table, scan is performed over the table. We will create a clustered index on the table and check the execution plan once again.
-- Create Clustered IndexCREATE CLUSTERED INDEX [IX_OneIndex_ID] ON [dbo].[OneIndex] ([ID] ASC) ON [PRIMARY] GO
Now, run following select on the table once again.
SELECT ID, FirstNameFROM OneIndexWHERE City = 'Las Vegas'GO
It is clear from execution plan that as a clustered index is created on the table, table scan is now converted to clustered index scan. In either case, base table is completely scanned and there is no seek on the table.
Now, let us see the WHERE clause of our table. From our basic observation, if we create an index on the column that contains the clause, a performance improvement may be obtained. Let us create non-clustered index on the table and then check the execution plan.
-- Create Index on Column City As that is used in where conditionCREATE NONCLUSTERED INDEX [IX_OneIndex_City] ON [dbo].[OneIndex] ([City] ASC) ON [PRIMARY] GO
After creating the non-clustered index, let us run our select statement again and check the execution plan.
SELECT ID, FirstNameFROM OneIndexWHERE City = 'Las Vegas'GO
As we have an index on the WHERE clause, the SQL Server query execution engine uses the non-clustered index to retrieve data from the table. However, the columns used in the SELECT clause are still not part of the index, and to display those columns, the engine will have to go to the base table again and retrieve those columns. This particular behavior is known as bookmark lookup or key lookup.
There are two different methods to resolve this issue. I have demonstrated both the methods together; however, it is recommended that you use any one of these methods for removing key lookup. I prefer Method 2.
Method 1: Creating non-clustered cover index.
In this method, we will create non-clustered index containing the columns, which are used in the SELECT statement, along with the column which is used in the WHERE clause.
CREATE NONCLUSTERED INDEX [IX_OneIndex_Cover] ON [dbo].[OneIndex] (City, FirstName, ID) ON [PRIMARY] GO
Once the above non-clustered index, which covers all the columns in query, is created, let us run the following SELECT statement and check our execution plan.
SELECT ID, FirstNameFROM OneIndexWHERE City = 'Las Vegas'GO
From the execution plan, we can confirm that key lookup is removed the only index seek is happening. As there is no key lookup, the SQL Server query engine does not have to go to retrieve the data from data pages and it obtains all the necessary data from index itself.

Method 2: Creating an included column non-clustered index.
Here, we will create non-clustered index that also includes the columns, which are used in the SELECT statement, along with the column used in the WHERE clause. In this method, we will use new syntax introduced in SQL Server 2005. An index with included nonkey columns can significantly improve query performance when all columns in the query are included in the index.
CREATE NONCLUSTERED INDEX [IX_OneIndex_Include] ON [dbo].[OneIndex] (City) INCLUDE (FirstName,ID) ON [PRIMARY] GO
From the execution plan, it is very clear that this method also removes the key lookup as well.

In summary, Key lookup, Bookmark lookup or RID lookup reduces the performance of query, and we can improve the performance of query by using included column index or cover index.
Discovering Unused Indexes
When SQL Server 2005 was introduced it added Dynamic Management Views (DMVs) that allow you to get additional insight as to what is going on within SQL Server. One of these areas is the ability to see how indexes are being used. There are two DMVs that we will discuss. Note that these views store cumulative data, so when SQL Server is restated the counters go back to zero, so be aware of this when monitoring your index usage.
DMV - sys.dm_db_index_operational_stats
This DMV allows you to see insert, update and delete information for various aspects for an index. Basically this shows how much effort was used in maintaining the index based on data changes.
If you query the table and return all columns, the output may be confusing. So the query below focuses on a few key columns. To learn more about the output for all columns you can check out Books Online.
SELECT OBJECT_NAME(A.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
A.LEAF_INSERT_COUNT,
A.LEAF_UPDATE_COUNT,
A.LEAF_DELETE_COUNT
FROM SYS.DM_DB_INDEX_OPERATIONAL_STATS (db_id(),NULL,NULL,NULL ) A
INNER JOIN SYS.INDEXES AS I
ON I.[OBJECT_ID] = A.[OBJECT_ID]
AND I.INDEX_ID = A.INDEX_ID
WHERE OBJECTPROPERTY(A.[OBJECT_ID],'IsUserTable') = 1
Below we can see the number of Inserts, Updates and Deletes that occurred for each index, so this shows how much work SQL Server had to do to maintain the index.

DMV - sys.dm_db_index_usage_stats
This DMV shows you how many times the index was used for user queries. Again there are several other columns that are returned if you query all columns and you can refer to Books Online for more information.
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS AS S
INNER JOIN SYS.INDEXES AS I ON I.[OBJECT_ID] = S.[OBJECT_ID] AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECTPROPERTY(S.[OBJECT_ID],'IsUserTable') = 1
AND S.database_id = DB_ID()
Here we can see seeks, scans, lookups and updates.
- The seeks refer to how many times an index seek occurred for that index. A seek is the fastest way to access the data, so this is good.
- The scans refers to how many times an index scan occurred for that index. A scan is when multiple rows of data had to be searched to find the data. Scans are something you want to try to avoid.
- The lookups refer to how many times the query required data to be pulled from the clustered index or the heap (does not have a clustered index). Lookups are also something you want to try to avoid.
- The updates refers to how many times the index was updated due to data changes which should correspond to the first query above.

Identifying Unused Indexes
So based on the output above you should focus on the output from the second query. If you see indexes where there are no seeks, scans or lookups, but there are updates this means that SQL Server has not used the index to satisfy a query but still needs to maintain the index. Remember that the data from these DMVs is reset when SQL Server is restarted, so make sure you have collected data for a long enough period of time to determine which indexes may be good candidates to be dropped.
No comments:
Post a Comment