Performance Issues
Ref:http://www.mssqltips.com/sqlservertutorial/264/performance-issues/
| Performance Issues |
Overview
There are several factors that can degrade SQL Server performance and in this section we will investigate some of the common areas that can effect performance. We will look at some of the tools that you can use to identify issues as well as review some possible remedies to fix these performance issues.
We will cover the following topics:
- Blocking
- Deadlocks
- I/O
- CPU
- Memory
- Role of statistics
- Query Tuning Bookmark Lookups
- Query Tuning Index Scans
| Troubleshooting Blocking (Performance Issues) |
Overview
In order for SQL Server to maintain data integrity for both reads and writes it uses locks, so that only one process has control of the data at any one time. There are serveral types of locks that can be used such as Shared, Update, Exclusive, Intent, etc... and each of these has a different behavior and effect on your data.
When locks are held for a long period of time they cause blocking, which means one process has to wait for the other process to finish with the data and release the lock before the second process can continue. This is similar to deadlocking where two processes are waiting on the same resource, but unlike deadlocking, blocking is resolved as soon as the first process releases the resource.
Explanation
As mentioned above, blocking is a result of two processes wanting to access the same data and the second process needs to wait for the first process to release the lock. This is how SQL Server works all of the time, but usually you do not see blocking because the time that locks are held is usually very small.
It probably makes sense that locks are held when updating data, but locks are also used when reading data. When data is updated an Update lock is used and when data is read a Shared lock is used. An Update lock will create an exclusive lock on the data for this process and a Shared lock allows other processes that use a Shared lock to access the data as well and when two processes are trying to access the same data this is where the locking and blocking occurs.
Here are various ways you can identify blocking for your SQL Server instance.
sp_who2
In a query window run this command:
sp_who2
This is the output that is returned. Here we can see the BlkBy column that shows SPID 60 is blocked by SPID 59.

Activity Monitor
In SSMS, right click on the SQL Server instance name and select Activity Monitor. In the Processes section you will see information similar to below. Here we can see similar information as sp_who2, but we can also see the Wait Time, Wait Type and also the resource that SPID 60 is waiting for.

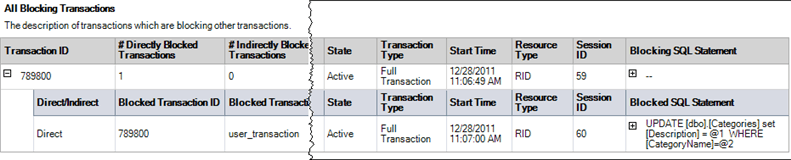
Report - All Blocking Transactions
Another option is to use the built in reports in SSMS. Right click on the SQL Server instance name and select Reports > Standard Reports > Activity - All Block Transactions.
Querying Dynamic Management Views
You can also use the DMVs to get information about blocking.
SELECT session_id, command, blocking_session_id, wait_type, wait_time, wait_resource, t.TEXT
FROM sys.dm_exec_requests
CROSS apply sys.dm_exec_sql_text(sql_handle) AS t
WHERE session_id > 50
AND blocking_session_id > 0
UNION
SELECT session_id, '', '', '', '', '', t.TEXT
FROM sys.dm_exec_connections
CROSS apply sys.dm_exec_sql_text(most_recent_sql_handle) AS t
WHERE session_id IN (SELECT blocking_session_id
FROM sys.dm_exec_requests
WHERE blocking_session_id > 0)
Here is the output and we can see the blocking information along with the TSQL commands that were issued.

| Tracing a SQL Server Deadlock (Performance Issues) |
Overview
A common issue with SQL Server is deadlocks. A deadlock occurs when two or more processes are waiting on the same resource and each process is waiting on the other process to complete before moving forward. When this situation occurs and there is no way for these processes to resolve the conflict, SQL Server will choose one of processes as the deadlock victim and rollback that process, so the other process or processes can move forward.
By default when this occurs, your application may see or handle the error, but there is nothing that is captured in the SQL Server Error Log or the Windows Event Log to let you know this occurred. The error message that SQL Server sends back to the client is similar to the following:
Msg 1205, Level 13, State 51, Line 3
Transaction (Process ID xx) was deadlocked on {xxx} resources with another process
and has been chosen as the deadlock victim. Rerun the transaction.
In this tutorial we cover what steps you can take to capture deadlock information and some steps you can take to resolve the problem.
Msg 1205, Level 13, State 51, Line 3
Transaction (Process ID xx) was deadlocked on {xxx} resources with another process
and has been chosen as the deadlock victim. Rerun the transaction.
Explanation
Deadlock information can be captured in the SQL Server Error Log or by using Profiler / Server Side Trace.
Trace Flags
If you want to capture this information in the SQL Server Error Log you need to enable one or both of these trace flags.
- 1204 - this provides information about the nodes involved in the deadlock
- 1222 - returns deadlock information in an XML format
You can turn on each of these separately or turn them on together.
To turn these on you can issue the following commands in a query window or you can add these as startup parameters. If these are turned on from a query window, the next time SQL Server starts these trace flags will not be active, so if you always want to capture this data the startup parameters is the best option.
DBCC TRACEON (1204, -1)
DBCC TRACEON (1222, -1)
Here is sample output for each of the trace flags.
DBCC TRACEON (1222, -1)
Trace Flag 1222 Output

Trace Flag 1204 Output

Profiler / Server Side Trace
Profiler works without the trace flags being turned on and there are three events that can be captured for deadlocks. Each of these events is in the Locks event class.
- Deadlock graph - Occurs simultaneously with the Lock:Deadlock event class. The Deadlock Graph event class provides an XML description of the deadlock.
- Lock: Deadlock - Indicates that two concurrent transactions have deadlocked each other by trying to obtain incompatible locks on resources that the other transaction owns.
- Lock: Deadlock Chain - Is produced for each of the events leading up to the deadlock.
Event Output
In the below image, I have only captured the three events mentioned above.

Deadlock Graph Output
Below is the deadlock graph which is the output for the Deadlock graph event. We can see on the left side that server process id 62 was selected as the deadlock victim. Also, if you hover over the oval with the X through it we can see the transaction that was running.
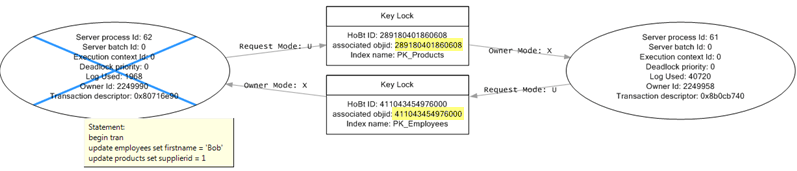
Finding Objects Involved in Deadlock
In all three outputs, I have highlighted the object IDs for the objects that are in contention. You can use the following query to find the object, substituting the object ID for the partition_id below.
SELECT OBJECT_SCHEMA_NAME([object_id]),
OBJECT_NAME([object_id])
FROM sys.partitions
WHERE partition_id = 289180401860608;
OBJECT_NAME([object_id])
FROM sys.partitions
WHERE partition_id = 289180401860608;
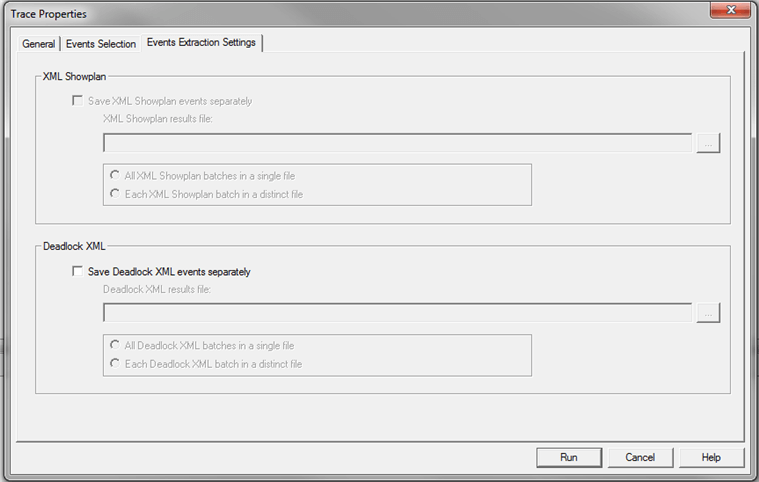
Saving Deadlock Graph Data in XML File
Since the deadlock graph data is stored in an XML format, you can save the XML events separately. When configuring the Trace Properties click on the Events Extraction Settings and enable this option as shown below.
Index Scans and Table Scans OverviewThere are several things that you can do to improve performance by throwing more hardware at the problem, but usually the place you get the most benefit from is when you tune your queries. One common problem that exists is the lack of indexes or incorrect indexes and therefore SQL Server has to process more data to find the records that meet the queries criteria. These issues are known as Index Scans and Table Scans.In this section will look at how to find these issues and how to resolve them. ExplanationAn index scan or table scan is when SQL Server has to scan the data or index pages to find the appropriate records. A scan is the opposite of a seek, where a seek uses the index to pinpoint the records that are needed to satisfy the query. The reason you would want to find and fix your scans is because they generally require more I/O and also take longer to process. This is something you will notice with an application that grows over time. When it is first released performance is great, but over time as more data is added the index scans take longer and longer to complete.To find these issues you can start by running Profiler or setting up a server side trace and look for statements that have high read values. Once you have identified the statements then you can look at the query plan to see if there are scans occurring. Here is a simple query that we can run. First use Ctrl+M to turn on the actual execution plan and then execute the query.
SELECT * FROM Person.Contact
Here we can see that this query is doing a Clustered Index Scan. Since this table has a clustered index and there is not a WHERE clause SQL Server scans the entire clustered index to return all rows. So in this example there is nothing that can be done to improve this query.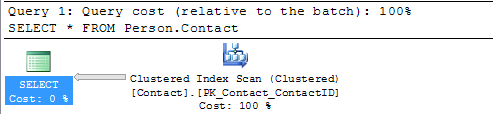
SELECT * FROM Person.Contact2
Here we can see that this query is doing a Table Scan, so when a table has a Clustered Index it will do a Clustered Index Scan and when the table does not have a clustered index it will do a Table Scan. Since this table does not have a clustered index and there is not a WHERE clause SQL Server scans the entire table to return all rows. So again in this example there is nothing that can be done to improve this query.
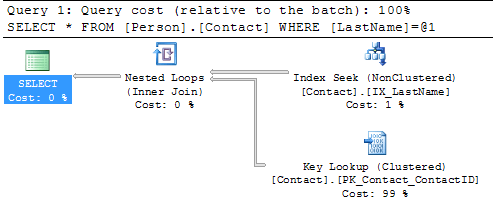
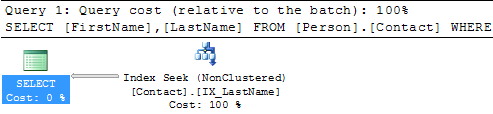
SELECT * FROM Person.Contact WHERE LastName = 'Russell'
Here we can see that we still get the Clustered Index Scan, but this time SQL Server is letting us know there is a missing index. If you right click on the query plan and select Missing Index Details you will get a new window with a script to create the missing index.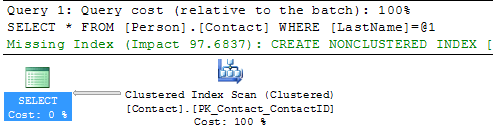
SELECT * FROM Person.Contact2 WHERE LastName = 'Russell'
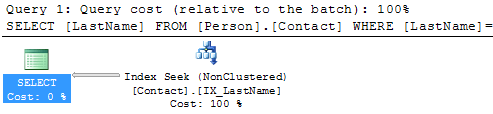
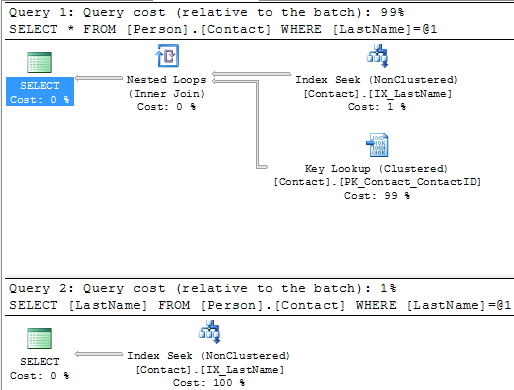
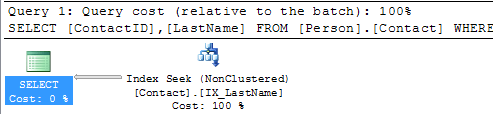
We can see that we still have the Table Scan, but SQL Server doesn't offer any suggestions on how to fix this. Below is the suggestion this tool provides and we can see that recommends creating a new index, so you can see that using both tools can be beneficial. 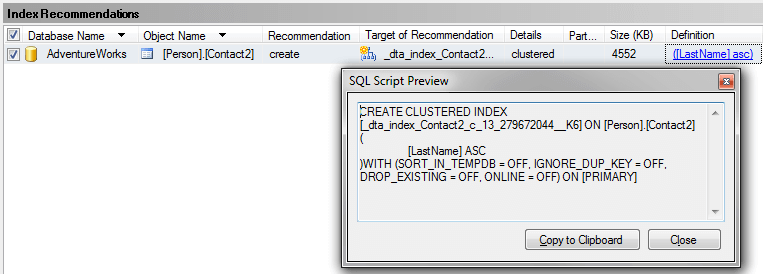 Create New IndexSo let's create the recommended index on Person.Contact and run the query again.USE [AdventureWorks] GO CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].[Contact] ([LastName]) GO SELECT * FROM Person.Contact WHERE LastName = 'Russell' 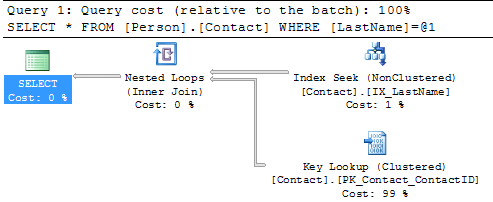 SummaryBy finding and fixing your Index Scans and Table Scans you can drastically improve performance especially for larger tables. So take the time to identify where your scans may be occurring and create the necessary indexes to solve the problem. One thing that you should be aware of is that too many indexes also causes issues, so make sure you keep a balance on how many indexes you create for a particular table.
|