
How to Solve Monitoring LSAlert Job Failed as Log shipping Report shows Red Even copy and restore Job Succeeded With DEMO
Primary Server

Primary Server LogShipping Report

Secondary Server













What is SQL Server log shipping?
SQL Server log shipping is a technique which involves two or more SQL Server instances and copying of a transaction log file from one SQL Server instance to another. The process of transferring the transaction log files and restoring is automated across the SQL Servers. As the process result there are two copies of the data on two separate locations
A log shipping session involves the following steps:
- Backing up the transaction log file on the primary SQL Server instance
- Copying the transaction log backup file across the network to one or more secondary SQL Server instances
- Restoring the transaction log backup file on the secondary SQL Server instances
Implementation examples
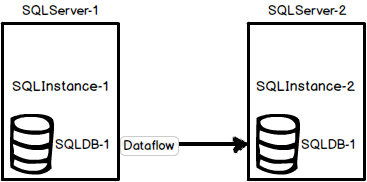
One of the common log shipping scenarios is the environment with two servers (SQLServer-1 – primary and SQLServer-2 – secondary), two SQL Server instances (SQLInstance-1 and SQLInstance-2), and one SQL Server database named SQLDB-1 with log shipping running on it
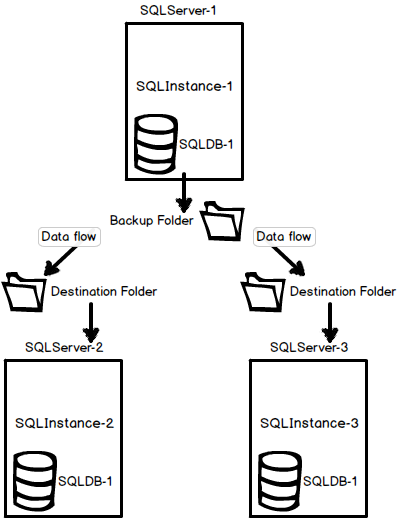
Another common configuration is the environment with three (or more) servers (SQLServer-1 – primary, SQLServer-2 – secondary, and SQLServer-3 – secondary), three SQL Server instances (SQLInstance-1, SQLInstance-2, and SQLInstance-3), and one SQL Server database named SQLDB-1 with log shipping running on it
Operating modes
There are two available modes and they are related to the state in which the secondary, log shipped, SQL Server database will be:
- Standby mode – the database is available for querying and users can access it, but in read-only mode
- The database is not available only while the restore process is running
- Users can be forced to disconnect when the restore job commence
- The restore job can be delayed until all users disconnect themselves
- The database is not available only while the restore process is running
- Restore mode – the database is not accessible
Advantages and disadvantages of using SQL Server log shipping
SQL Server log shipping is primarily used as a disaster recovery solution. Using SQL Server log shipping has multiple benefits: it’s reliable and tested in details, it’s relatively easy to set up and maintain, there is a possibility for failover between SQL Servers, data can be copied on more than one location etc.
Log shipping can be combined with other disaster recovery options such as AlwaysOn Availability Groups, database mirroring, and database replication. Also, SQL Server log shipping has low cost in human and server resources
The main disadvantages in the SQL Server log shipping technique are: need to manage all the databases separately, there isn’t possibility for an automatic failover, and secondary database isn’t fully readable while the restore process is running
Primary Server
Primary Server LogShipping Report
Secondary Server
Secondary Server LogShipping Report
Primary Server Job Info
Secondary Server Job Info
Here in Secondary server Monitoring Job is failing due to wrong scheduled restore job alert
Here copy job scheduled as 6 hours
Here Restore job scheduled as 6 hours but alert job scheduled as 45 mints it is conflict
To fix Need to schedule as 6 hours
After our change in alert now click submit to configured
Now we are running job
It went success now
see status as success
that is now Red alert issue is fixed it
Happy Blogging










































































