
Query asked on SQL Interviews
1)How to Get empid,empname,managerid,level on same table?
or
How to Get Hierarchy's Of employee who report to manager?
Solution:
AS
(
SELECT empid, name, mgrid, 0
FROM empmgrlevel
where mgrid is null
UNION ALL
SELECT E.empid, E.name, E.mgrid, M.lvl+1
FROM empmgrlevel AS E
JOIN EmpCTE AS M
ON E.mgrid = M.empid
)
SELECT * FROM EmpCTE
order by lvl


2)
SalesPerson table have id,name,age,salary
Order table have Orderno,id,amount
List Name of all salesperson who more than 1 order in order table?
Solution:
SELECT S.name,count(O.Orderno) as ordercount
from salesperson S
join orders O on s.sid=O.sid
Group by S.Name
having count(O.Orderno)>1


3) How to get second-highest salary employees in a table?
ex:-
1 alex 5000
2 gravin 7500
3 boxerlin 6580
4 manju 2850
5 meeralina 7459
6 asra 7458
SELECT *
FROM Employees
WHERE Salary = (SELECT MIN(Salary)
FROM (SELECT DISTINCT TOP (2) Salary
FROM Employees
ORDER BY Salary DESC) T)
(OR)
WITH T AS
(
SELECT *,
DENSE_RANK() OVER (ORDER BY Salary Desc) AS Rnk
FROM Employees
)
SELECT *
FROM T
WHERE Rnk=2;
Ans: 5 meeralina 7459
or
Select * from ( select Row_number() over ( order by salary desc ) as Row_INDEX ,
* From employees ) as Temp where Row_INDEX = 2
4)How to get the employees with their managers?

5)What is the difference among UNION, MINUS and INTERSECT?
UNION combines the results from 2 tables and eliminates duplicate records from the result set.
MINUS operator when used between 2 tables, gives us all the rows from the first table except the rows which are present in the second table.
INTERSECT operator returns us only the matching or common rows between 2 result sets.
To understand these operators, let’s see some examples. We will use two different queries to extract data from our emp table and then we will perform UNION, MINUS and INTERSECT operations on these two sets of data.
UNION
SELECT * FROM EMPLOYEE WHERE ID = 5 UNION SELECT * FROM EMPLOYEE WHERE ID = 6
| ID | MGR_ID | DEPT_ID | NAME | SAL | DOJ |
|---|---|---|---|---|---|
| 5 | 2 | 2.0 | Anno | 80.0 | 01-Feb-2012 |
| 6 | 2 | 2.0 | Darl | 80.0 | 11-Feb-2012 |
MINUS
SELECT * FROM EMPLOYEE MINUS SELECT * FROM EMPLOYEE WHERE ID > 2
| ID | MGR_ID | DEPT_ID | NAME | SAL | DOJ |
|---|---|---|---|---|---|
| 1 | 2 | Hash | 100.0 | 01-Jan-2012 | |
| 2 | 1 | 2 | Robo | 100.0 | 01-Jan-2012 |
INTERSECT
SELECT * FROM EMPLOYEE WHERE ID IN (2, 3, 5) INTERSECT SELECT * FROM EMPLOYEE WHERE ID IN (1, 2, 4, 5)
| ID | MGR_ID | DEPT_ID | NAME | SAL | DOJ |
|---|---|---|---|---|---|
| 5 | 2 | 2 | Anno | 80.0 | 01-Feb-2012 |
| 2 | 1 | 2 | Robo | 100.0 | 01-Jan-2012 |
What is the difference between WHERE clause and HAVING clause?
WHERE and HAVING both filters out records based on one or more conditions. The difference is, WHERE clause can only be applied on a static non-aggregated column whereas we will need to use HAVING for aggregated columns.
To understand this, consider this example.
Suppose we want to see only those departments where department ID is greater than 3. There is no aggregation operation and the condition needs to be applied on a static field. We will use WHERE clause here:
Suppose we want to see only those departments where department ID is greater than 3. There is no aggregation operation and the condition needs to be applied on a static field. We will use WHERE clause here:
SELECT * FROM DEPT WHERE ID > 3
| ID | NAME |
|---|---|
| 4 | Sales |
| 5 | Logistics |
Next, suppose we want to see only those Departments where Average salary is greater than 80. Here the condition is associated with a non-static aggregated information which is “average of salary”. We will need to use HAVING clause here:
SELECT dept.name DEPARTMENT, avg(emp.sal) AVG_SAL FROM DEPT dept, EMPLOYEE emp WHERE dept.id = emp.dept_id (+) GROUP BY dept.name HAVING AVG(emp.sal) > 80
| DEPARTMENT | AVG_SAL |
|---|---|
| Engineering | 90 |
As you see above, there is only one department (Engineering) where average salary of employees is greater than 80.
What is the difference between UNION and UNION ALL?
UNION and UNION ALL both unify for add two structurally similar data sets, but UNION operation returns only the unique records from the resulting data set whereas UNION ALL will return all the rows, even if one or more rows are duplicated to each other.
In the following example, I am choosing exactly the same employee from the emp table and performing UNION and UNION ALL. Check the difference in the result.
SELECT * FROM EMPLOYEE WHERE ID = 5 UNION ALL SELECT * FROM EMPLOYEE WHERE ID = 5
| ID | MGR_ID | DEPT_ID | NAME | SAL | DOJ |
|---|---|---|---|---|---|
| 5.0 | 2.0 | 2.0 | Anno | 80.0 | 01-Feb-2012 |
| 5.0 | 2.0 | 2.0 | Anno | 80.0 | 01-Feb-2012 |
SELECT * FROM EMPLOYEE WHERE ID = 5 UNION SELECT * FROM EMPLOYEE WHERE ID = 5
| ID | MGR_ID | DEPT_ID | NAME | SAL | DOJ |
|---|---|---|---|---|---|
| 5.0 | 2.0 | 2.0 | Anno | 80.0 | 01-Feb-2012 |
What is the difference between JOIN and UNION?
SQL JOIN allows us to “lookup” records on other table based on the given conditions between two tables. For example, if we have the department ID of each employee, then we can use this department ID of the employee table to join with the department ID of department table to lookup department names.
UNION operation allows us to add 2 similar data sets to create resulting data set that contains all the data from the source data sets. Union does not require any condition for joining. For example, if you have 2 employee tables with same structure, you can UNION them to create one result set that will contain all the employees from both of the tables.
SELECT * FROM EMP1
UNION
SELECT * FROM EMP2;
How to Deleting duplicate rows from a table?
;with T as ( select * , row_number() over (partition by Emp_ID order by Emp_ID) as rank from employee_test1 ) delete from T where rank > 1
The result is as:-
Emp_ID Emp_name Emp_Sal 1 Anees 1000 2 Rick 1200 3 John 1100 4 Stephen 1300 5 Maria 1400 6 Tim 1150
Finding TOP X records from each group
select pgm_main_category_id,pgm_sub_category_id,file_path from ( select pgm_main_category_id,pgm_sub_category_id,file_path, rank() over (partition by pgm_main_category_id order by pgm_sub_category_id asc) as rankid from photo_test ) photo_test where rankid < 3 -- replace 3 by any number 2,3 etc for top2 or top3. order by pgm_main_category_id,pgm_sub_category_idThe result is as:-
pgm_main_category_id pgm_sub_category_id file_path 17 15 photo/bb1.jpg 17 16 photo/cricket1.jpg 18 18 photo/forest1.jpg 18 19 photo/tree1.jpg 19 21 photo/laptop1.jpg 19 22 photocamer1.jpg
ROW_NUMBER assigns contiguous, unique numbers from 1.. N to a result set.
RANK does not assign unique numbers—nor does it assign contiguous numbers. If two records tie for second place, no record will be assigned the 3rd rank as no one came in third, according to RANK. See below:
SELECT name, sal, rank() over(order by sal desc) rank_by_sal FROM EMPLOYEE o
| name | Sal | RANK_BY_SAL |
|---|---|---|
| Hash | 100 | 1 |
| Robo | 100 | 1 |
| Anno | 80 | 3 |
| Darl | 80 | 3 |
| Tomiti | 70 | 5 |
| Pete | 70 | 5 |
| Bhuti | 60 | 7 |
| Meme | 60 | 7 |
| Inno | 50 | 9 |
| Privy | 50 | 9 |
DENSE_RANK, like RANK, does not assign unique numbers, but it does assign contiguous numbers. Even though two records tied for second place, there is a third-place record. See below:
SELECT name, sal, dense_rank() over(order by sal desc) dense_rank_by_sal FROM EMPLOYEE o
| name | Sal | DENSE_RANK_BY_SAL |
|---|---|---|
| Hash | 100 | 1 |
| Robo | 100 | 1 |
| Anno | 80 | 2 |
| Darl | 80 | 2 |
| Tomiti | 70 | 3 |
| Pete | 70 | 3 |
| Bhuti | 60 | 4 |
| Meme | 60 | 4 |
| Inno | 50 | 5 |
| Privy | 50 | 5 |
Generating a row number – that is a running sequence of numbers for each row is not easy using plain SQL. In fact, the method I am going to show below is not very generic either. This method only works if there is at least one unique column in the table. This method will also work if there is no single unique column, but collection of columns that is unique. Anyway, here is the query:
SELECT name, sal, (SELECT COUNT(*) FROM EMPLOYEE i WHERE o.name >= i.name) row_num FROM EMPLOYEE o order by row_num
| NAME | SAL | ROW_NUM |
|---|---|---|
| Anno | 80 | 1 |
| Bhuti | 60 | 2 |
| Darl | 80 | 3 |
| Hash | 100 | 4 |
| Inno | 50 | 5 |
| Meme | 60 | 6 |
| Pete | 70 | 7 |
| Privy | 50 | 8 |
| Robo | 100 | 9 |
| Tomiti | 70 | 10 |
What are joins and Types of join?
We need retrive data from two or more tables to make our result complete. We need to perform a join.
INNER JOIN
INNER JOIN
This join returns rows when there is at least one match in both the tables.
OUTER JOIN
There are three different Outer Join methods.
LEFT OUTER JOIN
This join returns all the rows from the left table with the matching rows from the right table. If there are no field matching in the right table then it returns NULL values
RIGHT OUTER JOIN
Right outer join returns all the rows from the right table with the matching rows from the left table. If there are no field matching in the left table then it returns NULL values
FULL OUTER JOIN
Full outer join merge left outer join and right outer join. this returns row from either table when the conditions are met and returns null value when there is no match
CROSS JOIN
Corss join is does not necessary any condition to join. The output result contains records that are multiplication of record from both the tables.
What is the difference between inner and outer join? Explain with example.
Inner Join
Inner join is the most common type of Join which is used to combine the rows from two tables and create a result set containing only such records that are present in both the tables based on the joining condition (predicate).
Inner join returns rows when there is at least one match in both tables
If none of the record matches between two tables, then INNER JOIN will return a NULL set. Below is an example of INNER JOIN and the resulting set.
SELECT dept.name DEPARTMENT, emp.name EMPLOYEE FROM DEPT dept, EMPLOYEE emp WHERE emp.dept_id = dept.id
| Department | Employee |
|---|---|
| HR | Inno |
| HR | Privy |
| Engineering | Robo |
| Engineering | Hash |
| Engineering | Anno |
| Engineering | Darl |
| Marketing | Pete |
| Marketing | Meme |
| Sales | Tomiti |
| Sales | Bhuti |
Outer Join
Outer Join can be full outer or single outer
Outer Join, on the other hand, will return matching rows from both tables as well as any unmatched rows from one or both the tables (based on whether it is single outer or full outer join respectively).
Notice in our record set that there is no employee in the department 5 (Logistics). Because of this if we perform inner join, then Department 5 does not appear in the above result. However in the below query we perform an outer join (dept left outer join emp), and we can see this department.
SELECT dept.name DEPARTMENT, emp.name EMPLOYEE FROM DEPT dept, EMPLOYEE emp WHERE dept.id = emp.dept_id (+)
| Department | Employee |
|---|---|
| HR | Inno |
| HR | Privy |
| Engineering | Robo |
| Engineering | Hash |
| Engineering | Anno |
| Engineering | Darl |
| Marketing | Pete |
| Marketing | Meme |
| Sales | Tomiti |
| Sales | Bhuti |
| Logistics |
The (+) sign on the emp side of the predicate indicates that emp is the outer table here. The above SQL can be alternatively written as below (will yield the same result as above):
SELECT dept.name DEPARTMENT, emp.name EMPLOYEE FROM DEPT dept LEFT OUTER JOIN EMPLOYEE emp ON dept.id = emp.dept_id
Query to Display Duplicate Count only in table:
create table Sampledata(sid int,sname varchar(30),age int)
insert into Sampledata
select 121,'mark',25
union
select 121,'taylor',30
union
select 125,'zahos',35
union
select 127,'parves',43
union
select 132,'jerar',34
union
select 135,'James',25
union
select 135,'saylor',22
union
select 135,'Tayolr',33
select * from Sampledata

Display Duplicate Count in Table:
SELECT sid,COUNT(*) Count_Duplicate
FROM Sampledata
GROUP BY sid
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC

Row_number() over(partition by order by) Command
as see below.

Write Query to Find B shaded Area?

Solution:
SELECT * FROM TableA
RIGHT OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableA.id IS null
How to achieve this as comma seperated Value in SQL using XML METHOD?
There are many scenarios where we have to show the values of column value as comma (or any other special character) separated
string in result set.
This can be easily achieved using XML path method in SQL.
Let's take an example of ProductDetails Table:
Hide Copy Code
SELECT * FROM ProductDetails
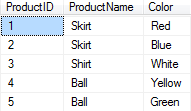
Now suppose we want to fetch the list of products along with available colors where multiple colors are shown as comma separated
string.
Hide Copy Code
SELECT DISTINCT p.ProductName,
STUFF((SELECT distinct ',' + p1.[Color]
FROM ProductDetails p1
WHERE p.ProductName = p1.ProductName
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'') Color
FROM ProductDetails p;

Comma Separated Values (CSV) from Table Column Normal Method:
Example 1:
USE AdventureWorksGO-- Check Table ColumnSELECT [Name]FROM HumanResources.ShiftGO-- Get CSV valuesSELECT STUFF((SELECT ',' + s.NameFROM HumanResources.Shift sORDER BY s.NameFOR XML PATH('')),1,1,'') AS CSVGO |
 from Table Column Part 2")
Example 2:USE AdventureWorks
GO-- Check Table ColumnSELECT NameFROM HumanResources.Shift
GO-- Get CSV valuesSELECT SUBSTRING(
(SELECT ',' + s.NameFROM HumanResources.Shift sORDER BY s.NameFOR XML PATH('')),2,200000) AS CSV
GO
I consider XML as the best solution in terms of code and performance..
 from Table Column")
Example 3:
DECLARE @listStr VARCHAR(MAX)SELECT @listStr = COALESCE(@listStr+',' , '') + NumberColsFROM NumberTableSELECT @listStr
DECLARE @listStr VARCHAR(MAX)SELECT @listStr = COALESCE(@listStr+',' , '') + NumberColsFROM NumberTableSELECT @listStr
No comments:
Post a Comment